
前言
上一次分享了 CAP 定理,我們了解到在有網路分區(Partition)的情況下,我們只能在一致性(Consistency)與可用性(Availability)之間二擇一,更進一步地說,我們其實是在光譜的兩端 — 強一致性(Strong Consistency)與最終一致性(Eventually Consistency)之間做選擇。
在最終一致性上,我們通常會聽到很多方法論,像是上篇提到的讀時修復(Read Repair)、寫時修復(Write Repair)、反熵(Anti-Entropy)等等;不過在強一致性上,我們比較常聽到某論文發表的強一致性演算法,原因是強一致性要有合理的數學佐證,大家才會相信,除此之外,還需要經過大規模的落地驗證,大家才會對其效能認可,因此被廣泛運用在商業上的強一致性算法比較少,經典常見的像是 Paxos 、 ZooKeeper 的 ZAB 、 Raft 等等。

在開始之前,如果還沒讀過上一篇《分散式架構的限制理論 — CAP 定理》的,建議可以先閱讀理解分散式系統的限制。由於強一致性在某些場景是必須要被保證的,像是金融支付、票務系統等等,所以這篇會介紹強一致性系列的算法。
Paxos 共識演算法家族
若要說到共識演算法,那一定會提及 Paxos,原因是 Paxos 剛被提出時缺少工程面的實作細節,比較像個理論框架,導致後面有實作細節的算法看起來都像 Paxos,甚至有人會說「這世界只有一種共識演算法,那就是 Paxos」。這裡暫時不會展開 Paxos 的細節,因為 Paxos 算法是出名的難,導致後來作者 Lamport 甚至還自己出了《Paxos Made Simple》來解釋自己的算法,不過這裡提及 Paxos 是因為 Paxos 的重要性在於它有嚴謹的數學證明,如果真的想理解 Paxos,建議可以先理解 Paxos 家族的其他演算法,像是本篇要提到的 Raft,最後如果對於 Paxos 在工程端的實作有興趣的,可以參考 Google 團隊對 Paxos 的實戰總結《Paxos Made Live — An Engineering Perspective》。
共識演算法分類 — BFT vs. CFT
從解決的問題類型來看,共識演算法分成兩種,分別是拜占庭容錯演算法(Byzantine Fault Tolerance, BFT)與故障容錯演算法(Crash Fault Tolerance, CFT)。拜占庭容錯演算法主要在解決如果有節點作惡的情況下,如何同步集群的狀態,常見的拜占庭容錯演算法有 PBFT;故障容錯演算法主要都在處理節點故障或是遇到網路問題時,如何讓整個集群的狀態維持一致,常見的故障容錯演算法有 ZAB 、 Raft 等等。
雖然拜占庭問題(Byzantine Generals’ Problem)跟拜占庭容錯演算法 PBFT 被提出的時間都相當早,但可以說是到了區塊鏈出現,才找到大規模的應用場景,而大部分企業內部應用的,還是屬於故障容錯演算法,像是 Google 透過 Paxos 達成共識的分布式鎖系統 — Chubby,而今天我們要介紹的就是常見於企業內部的共識機制 — Raft 。
Raft 共識機制
Raft 是 Diego Ongaro 在 Stanford 念博班時的博士論文,在 2013 年與他的指導教授 John Ousterhout 一同撰寫《In Search of an Understandable Consensus Algorithm》,並在 2014 年的 USENIX Annual Technical Conference 上獲得 Best Paper Award 。
從論文名稱就可以看出作者們有多想表達其他共識機制不好理解,一個好理解的算法最大的優點就是,在工程面上不容易出錯,這也導致了 2013 年後的新系統如果需要強一致性,通常會優先考慮 Raft,像是 2013 年的 etcd 、 InfluxDB 、 2014 年的 Consul 、 IPFS 以及 2015 年的 CockroachDB 等等;在聯盟鏈鏈裡,通常也會把 Raft 當共識演算法的選擇之一,像是 Corda 、 Quorum 以及 1.4.1 版後的 Fabric,雖然 Raft 不是拜占庭容錯演算法,但在大家可以互相信任彼此的情況下,聯盟鏈還是可以以 Raft 為共識機制。好理解的另一個優勢就是實作的人相當多,所以可以找到相當多的參考,甚至是作者參與實作的版本,大家上 GitHub 搜尋 Paxos 及 Raft,就會發現兩者光是在 Repostiory 數量就有近 3 倍的差距。
接下來我會介紹 Raft 演算法的細節,會從節點記錄的內容 — 狀態(State)、任期(Term)、日誌(Log)及資料狀態機(State Machine)開始,接著說明兩大模組 — 領導者選舉(Leader Election)及日誌複製(Log Replication)。這篇只探討理論,之後有機會的話,我會再寫一篇探討 Hashicorp Raft 原始碼的文章。
節點狀態(State)
在 Raft 裡面,節點有三種狀態,分別是 — 領導者(Leader)、候選人(Candidate)及跟隨者(Follower)。 Raft 屬於強領導者模型(Strong Leader),所以一個 Raft 集群中只能存在一個領導者,其他節點會以領導者為尊,領導者說什麼就是什麼,這也導致了 Raft 只能做到故障容錯(CFT),而無法處理拜占庭容錯(BFT)。

任期(Term)
任期聽起來是只有領導者才需要的東西,沒錯,但是 Raft 為了做到故障容錯,在集群裡面的任一個節點都有可能在領導者故障後成為候選人,並參與領導者選舉,所以每個節點都要知道現在的任期。
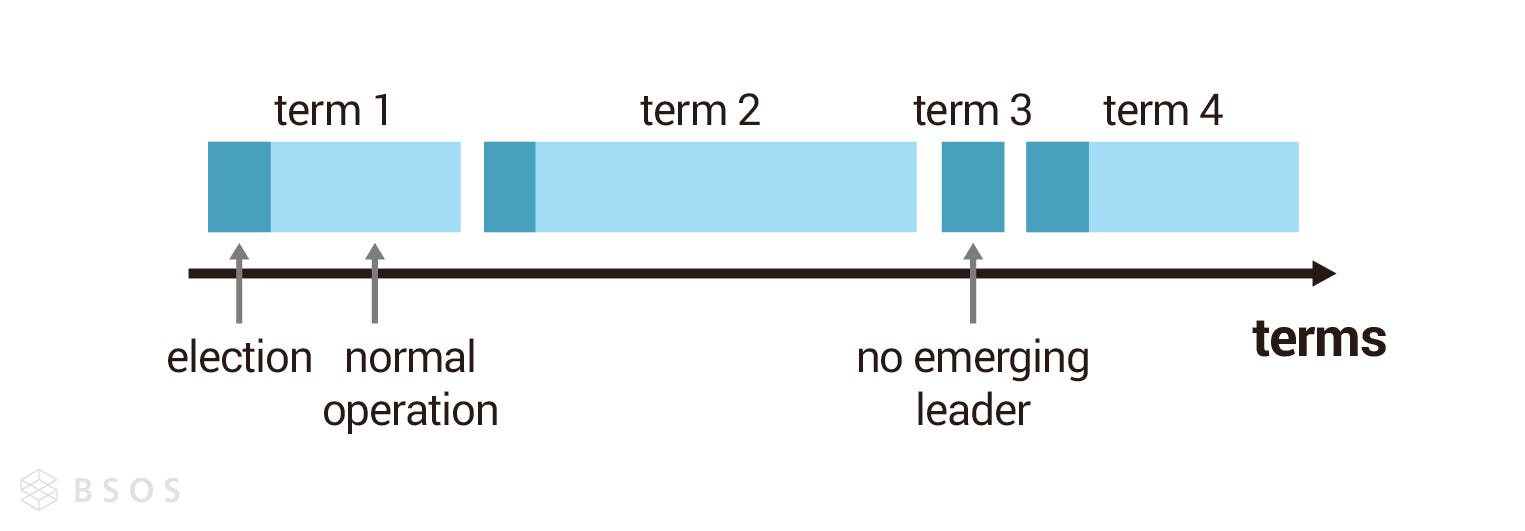
任期是一個嚴格遞增的數字,Raft 是強領導者模型,所以一個任期內至多只會有一個領導者,只有有領導者在的時間,才能對外提供服務。以下圖為例,每個任期一開始都是領導者選舉(藍色區段),後面是集群可以對外服務的時間(綠色區段),每一個任期只有在領導者故障後,集群才會發起下一次的選舉,所以每次任期的時間長度不固定,也有可能發生領導者選舉失敗的任期(如 t3),代表該任期沒有領導者,所以直接進行下一輪的領導者選舉。
日誌(Log)
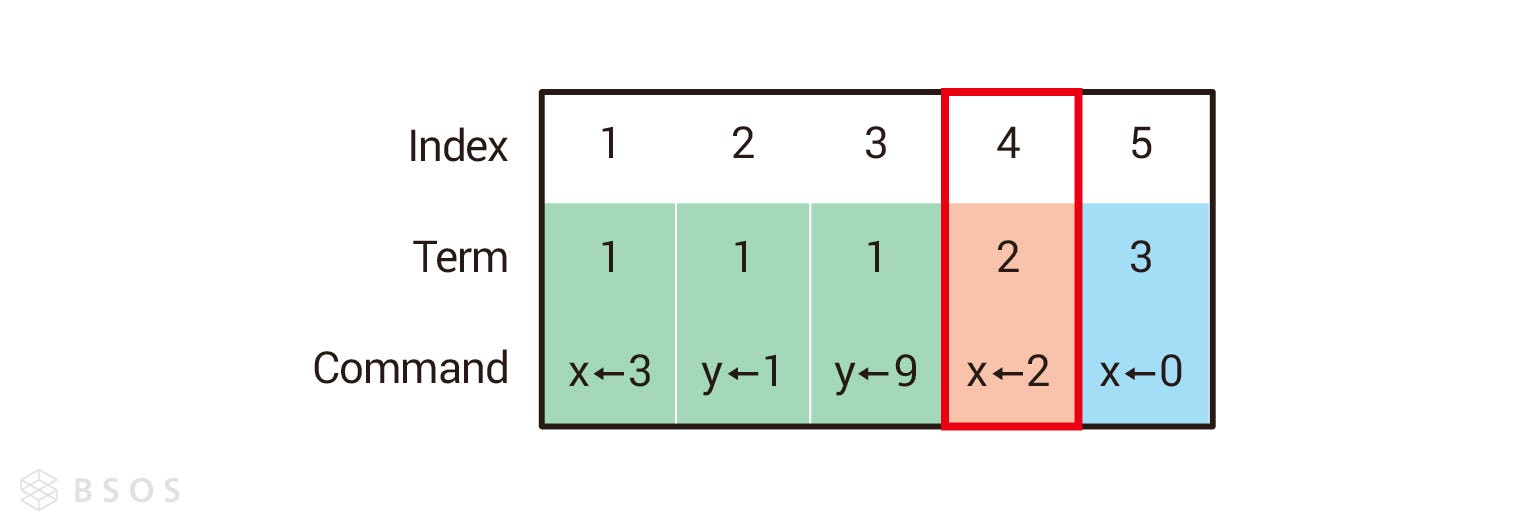
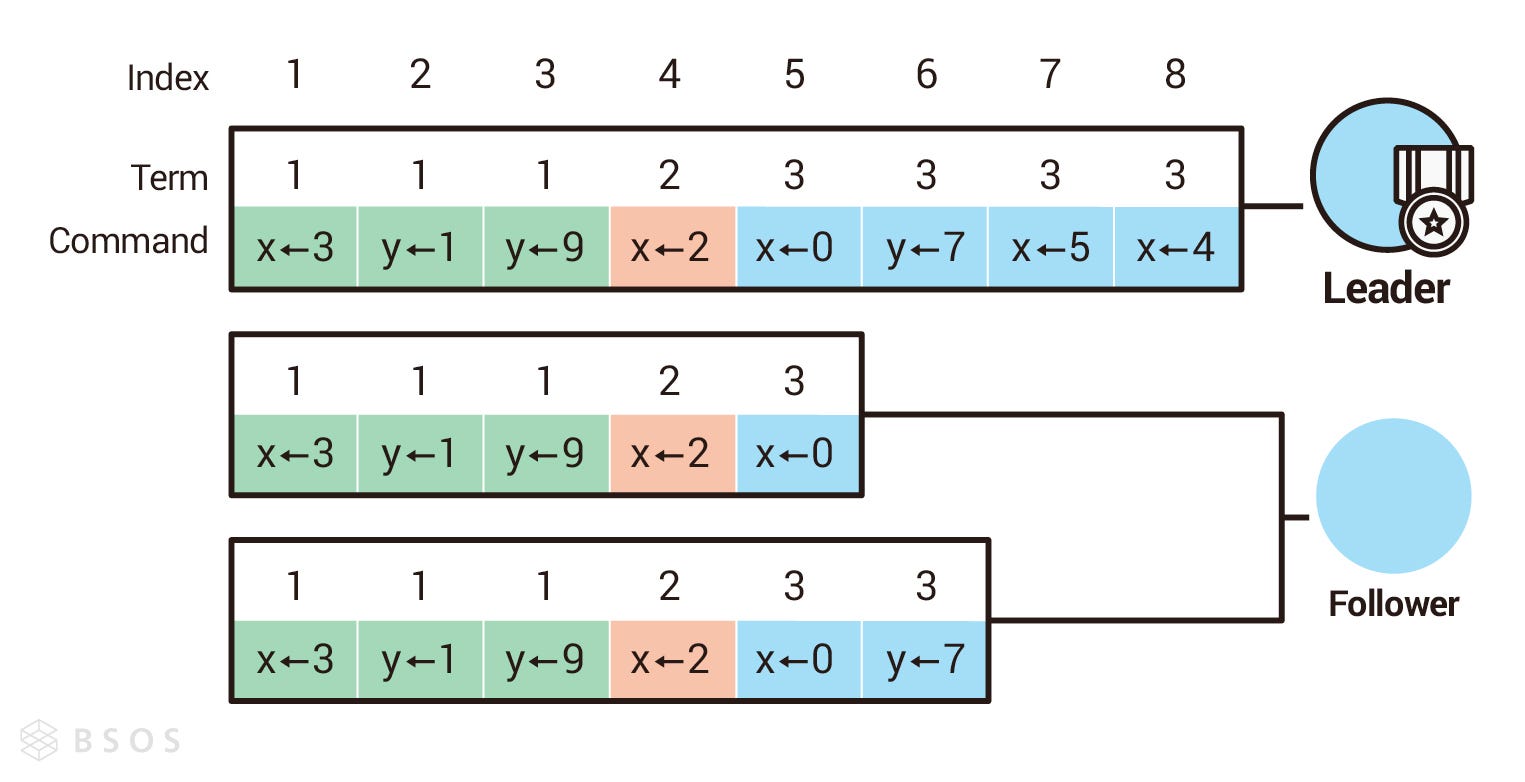
日誌由索引(Index)、任期(Term)及指令(Command)組成,索引一樣是個嚴格遞增的數字,任期在這裡代表在哪個任期記錄的日誌,指令代表要做什麼操作。以下圖為例,紅色框框圈起來的代表「日誌索引 4 發生在任期 2,指令是把 x 設定成 2」。
資料狀態機(State Machine)
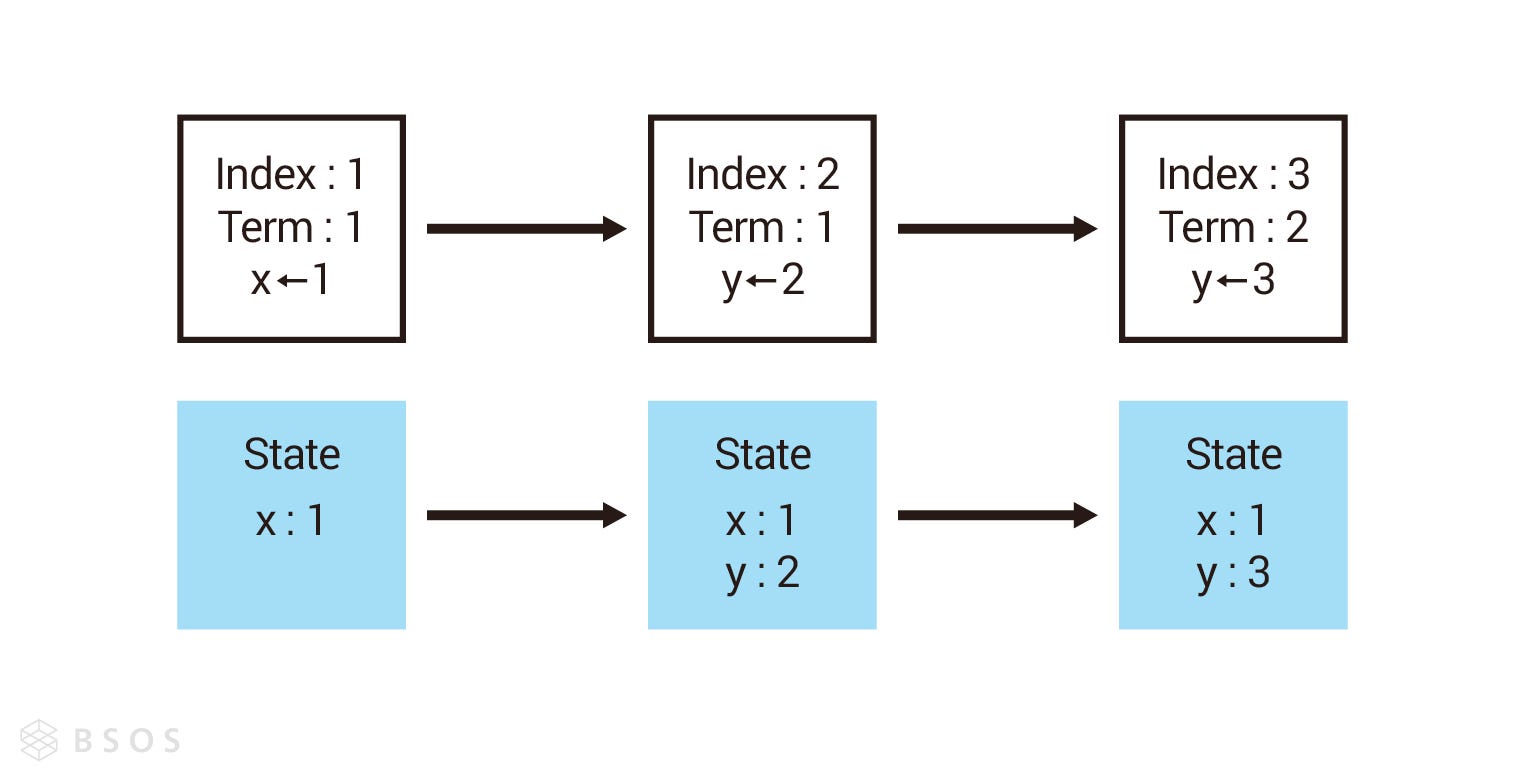
State Machine 的中文翻譯應該是狀態機,但這裡我們用資料狀態機比較好跟節點狀態區分。 Raft 透過日誌記錄使用者發送的指令,但寫進日誌只是一個記錄,並不代表資料的狀態真的改變了,在日誌複製那節,我會再說明從新增日誌到改變資料狀態的條件,但這裡我們先知道新增日誌跟改變資料狀態是兩回事。
上一篇有提到 CP 模型通常會用兩階段提交(Two-Phase Commit, 2PC),這也是為什麼 Raft 要把日誌跟資料狀態機分開的原因,寫進日誌是第一階段,改變資料狀態機是第二階段。以下圖為例,假設每次新增日誌都達成改變資料狀態的條件,那資料的狀態也會隨著日誌裡的指令而改變。
領導者選舉(Leader Election)
上面我們有提到節點有三種狀態 — 跟隨者(Follower)、候選人(Candidate)以及領導者(Leader),以下我們就依據不同的節點狀態及每個狀態可能會遇到的事件,來理解 Raft 領導者選舉的機制。
跟隨者(Follower)
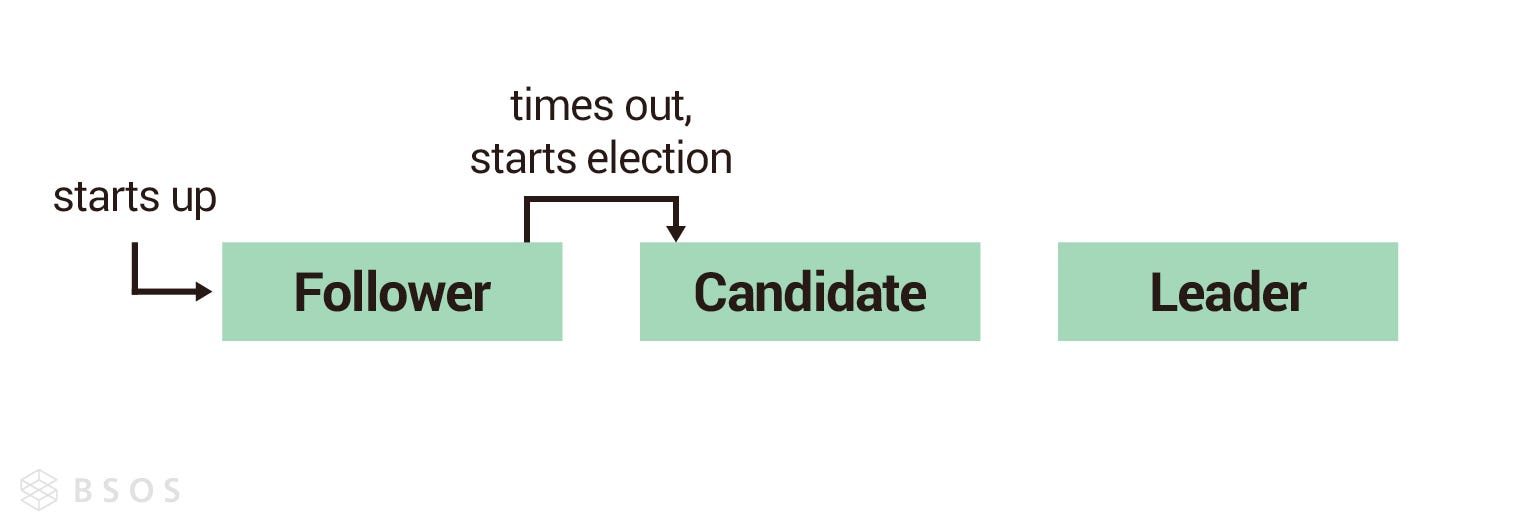
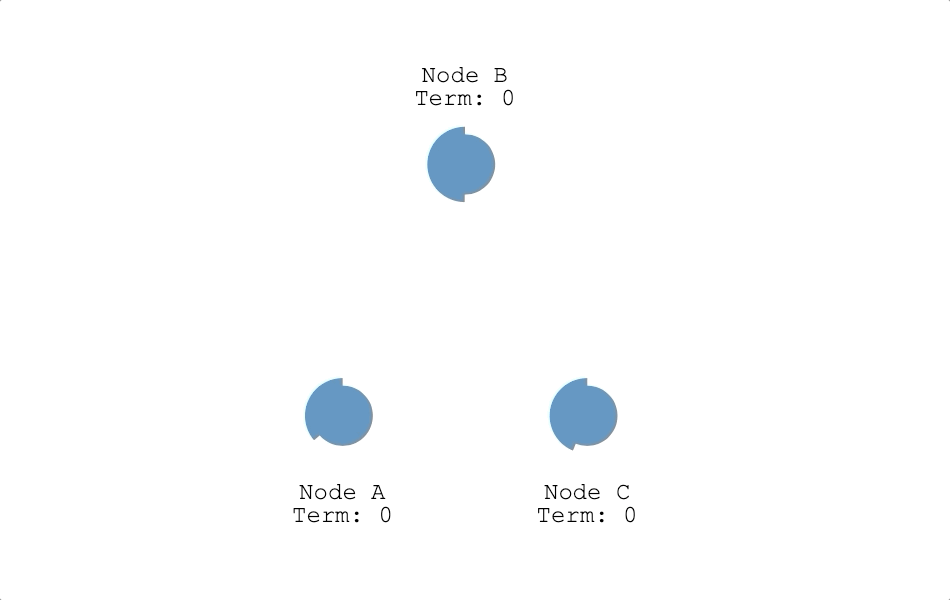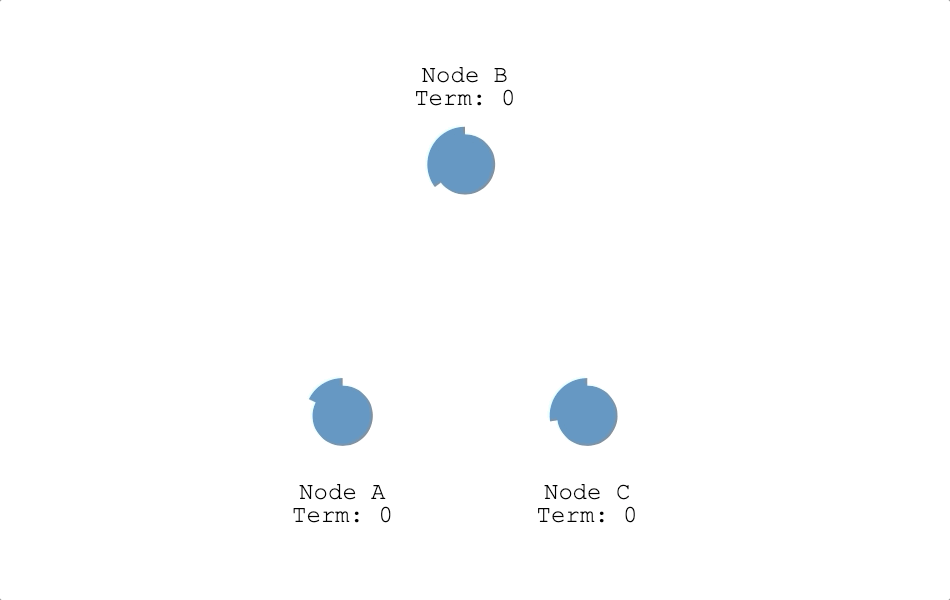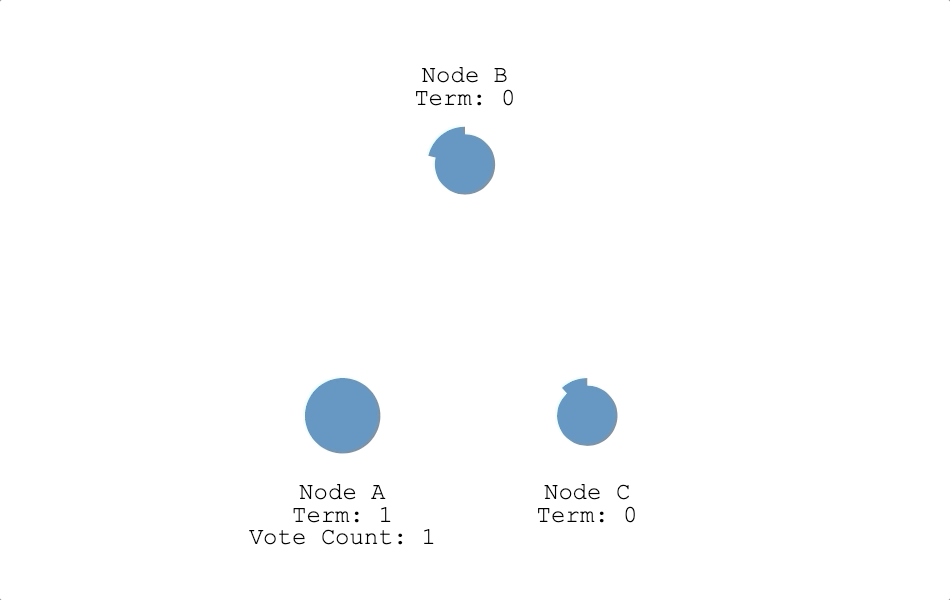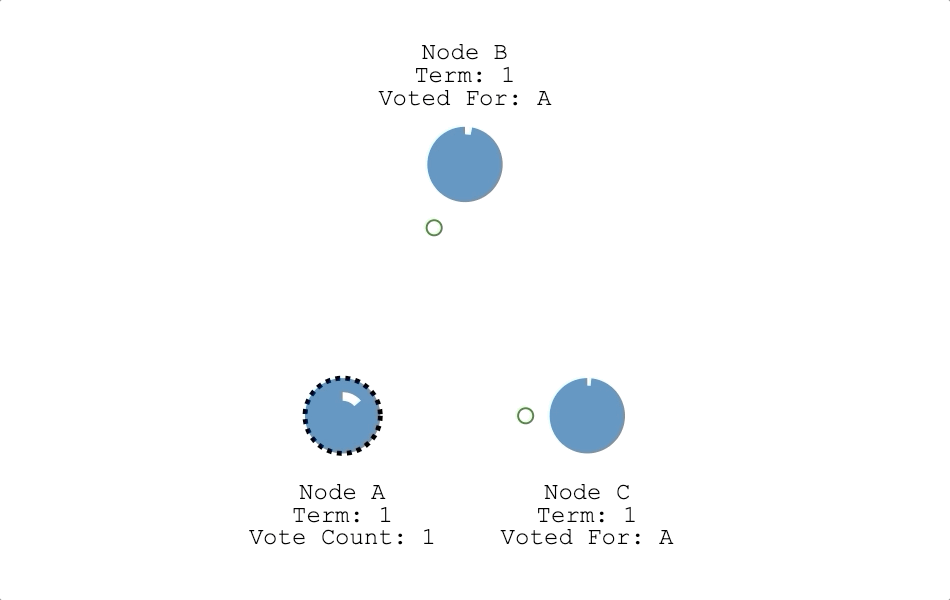
每個節點剛啟動時都是跟隨者,跟隨者會維護領導者心跳信息的計時器(Timer),依據計時器倒數的結果,會有下面兩種可能:
- 繼續當跟隨者:計時器倒數為 0 前,收到領導者心跳信息(Heartbeat)或是候選人投票請求訊息(RequestVote RPC),節點會重置倒數鐘繼續當跟隨者(如下圖節點 B 跟 C)。
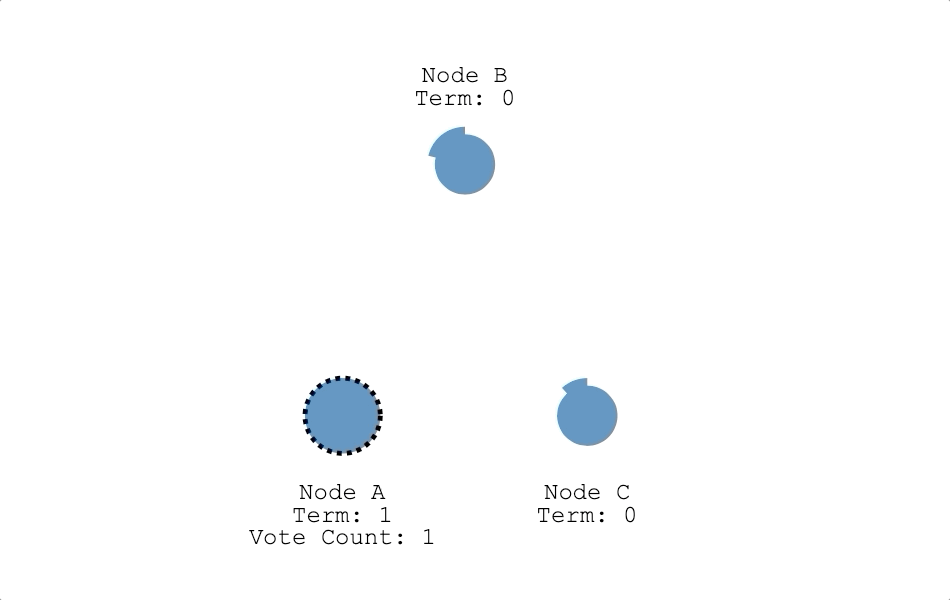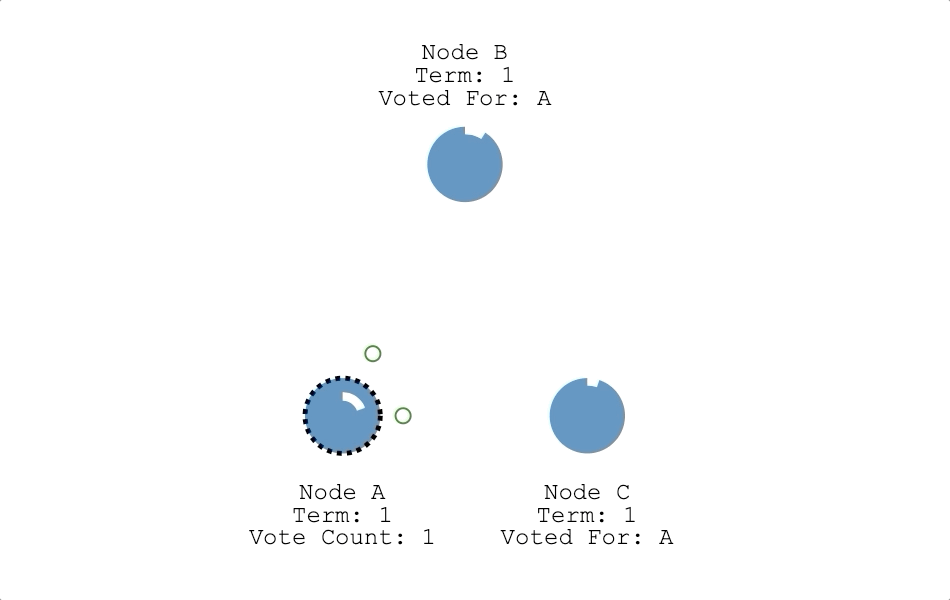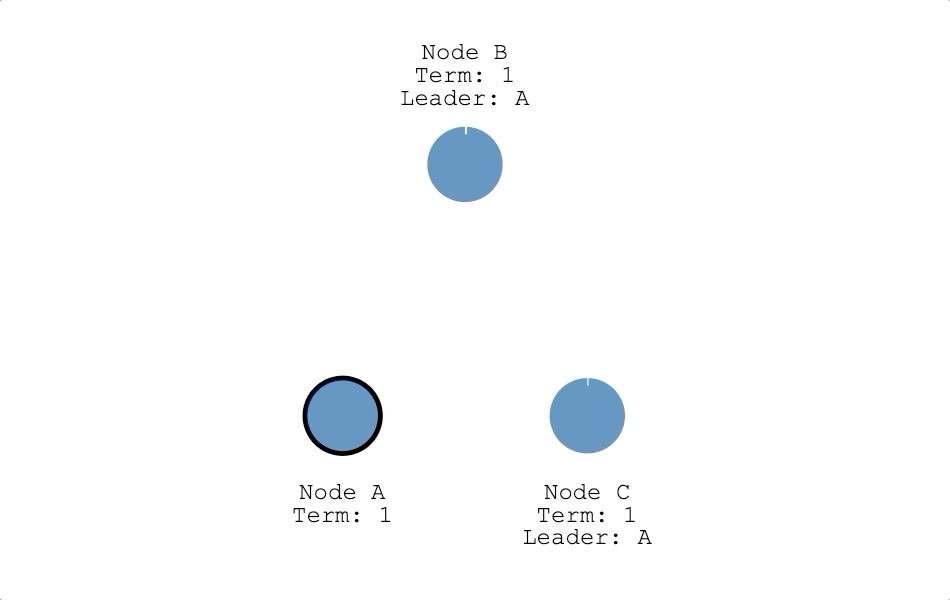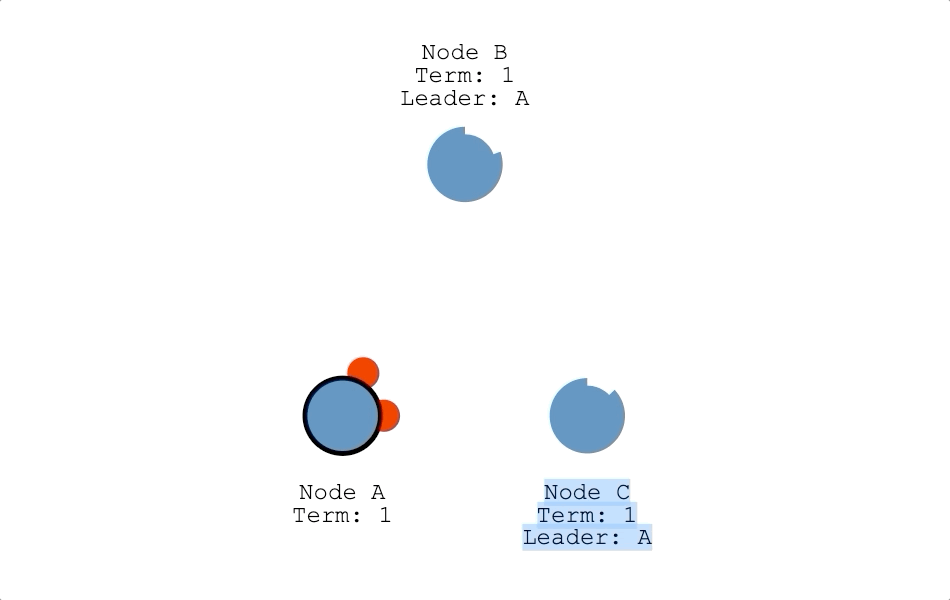
- 成為候選人:計時器倒數為 0 時,都沒收到領導者心跳信息,也沒有收到其他候選人的訊息,跟隨者判定現在集群裡沒有領導者而發起選舉,變成候選人。節點從跟隨者變成候選人時會把自己的任期(Term)加一,並投自己一票(如下圖節點 A)。上面有提到一個任期最多只會有一個領導者,所以節點在發起選舉時把任期加一,代表節點認為上個任期已經結束了,進入下一個任期。
候選人(Candidate)
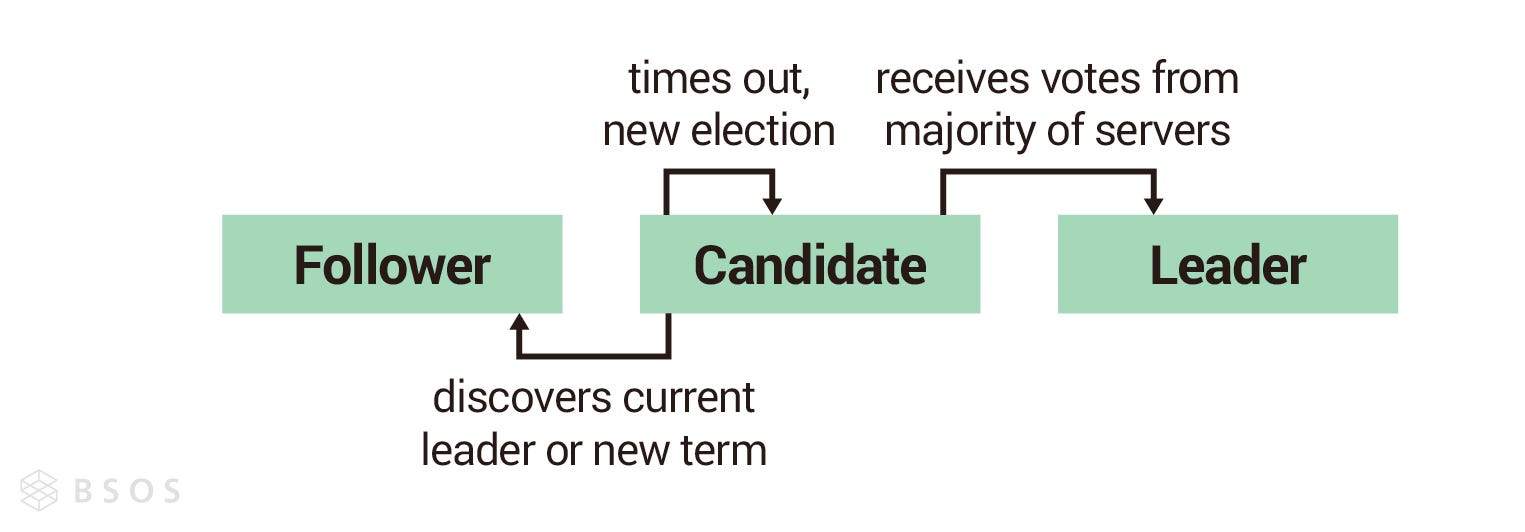
節點成為候選人後會立即向每個節點發出投票請求(RequestVote RPC),並維護一個選舉超時(Election Timeout)的計時器,依據投票結果,會有下面三種情況:
- 成為領導者:只要候選人獲得超過半數的票數,候選人就會把自己的狀態改成領導者(如下圖節點 A),並開始對其他節點發送心跳信息。
- 退回跟隨者:候選人在選舉期間發現已經有同任期的領導者,或者是更高任期的領導者時,把自己的狀態改回跟隨者。
- 選舉超時(Election timeout):當候選人的倒數鐘倒數為 0 時,自己沒辦法變成領導者,也沒有接到其他領導者的心跳信息,此時節點會判定這次選舉失敗,開始下一次的選舉,候選人會把自己的任期加一,代表新任期的開始,同時把自己的票數重置為 1,最後向其他節點再次發送投票請求。
領導者(Leader)

節點在擔任領導者期間,會持續向其他節點發送心跳信息,防止其他節點舉辦選舉,但集群也可能因為分區(Partition)而有兩個領導者,當分區恢復後,其中一位領導者發現另一位領導者任期比他高時,任期低的領導者會退回跟隨者,讓集群恢復只有一位領導者的狀態。
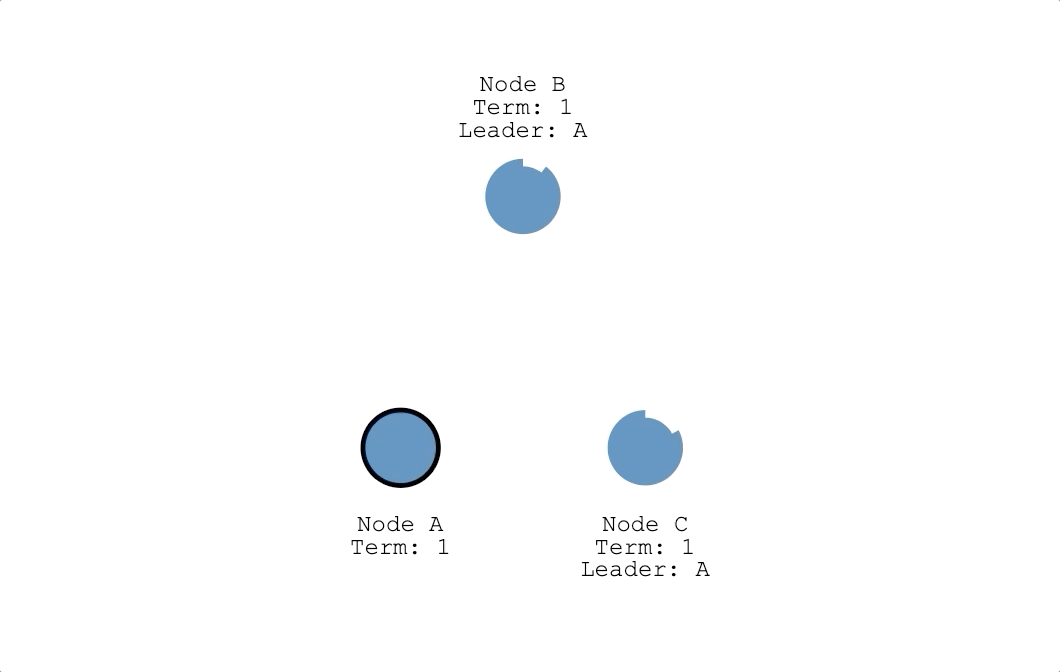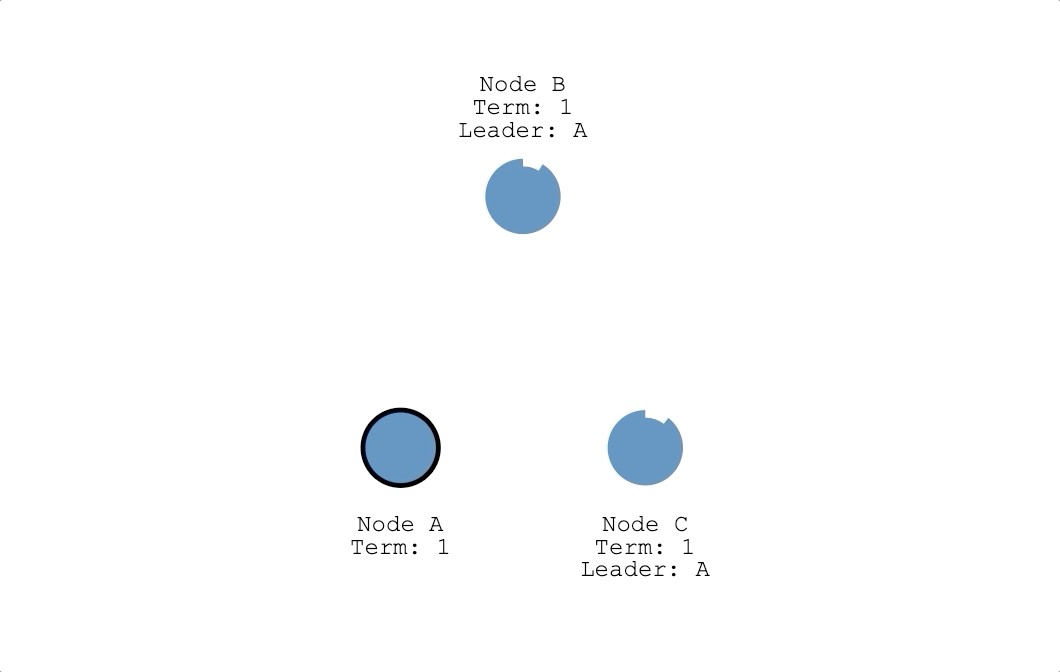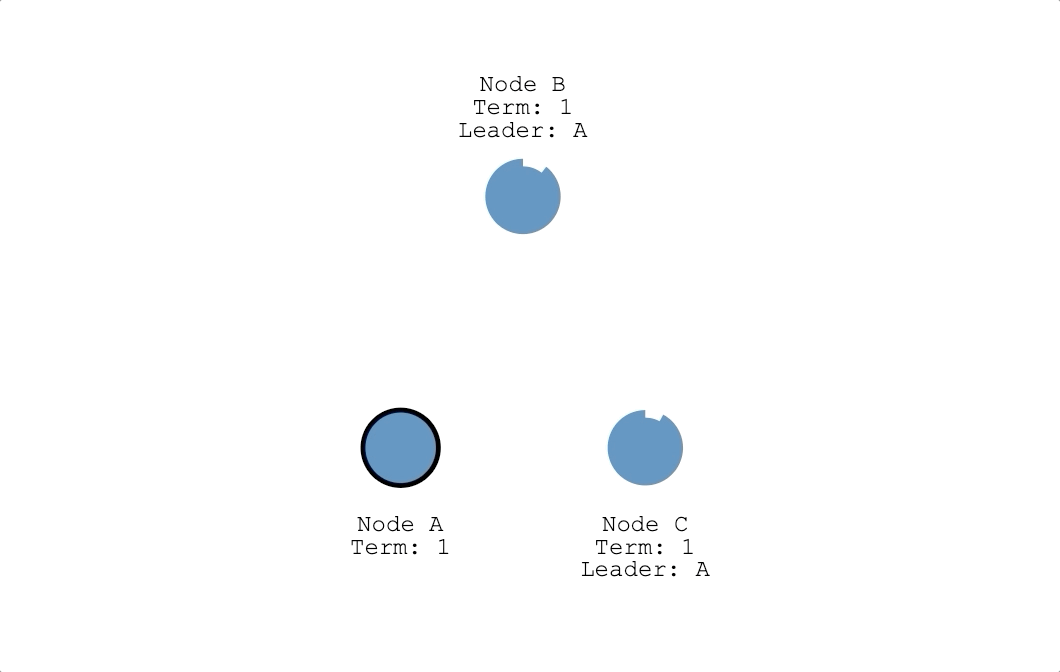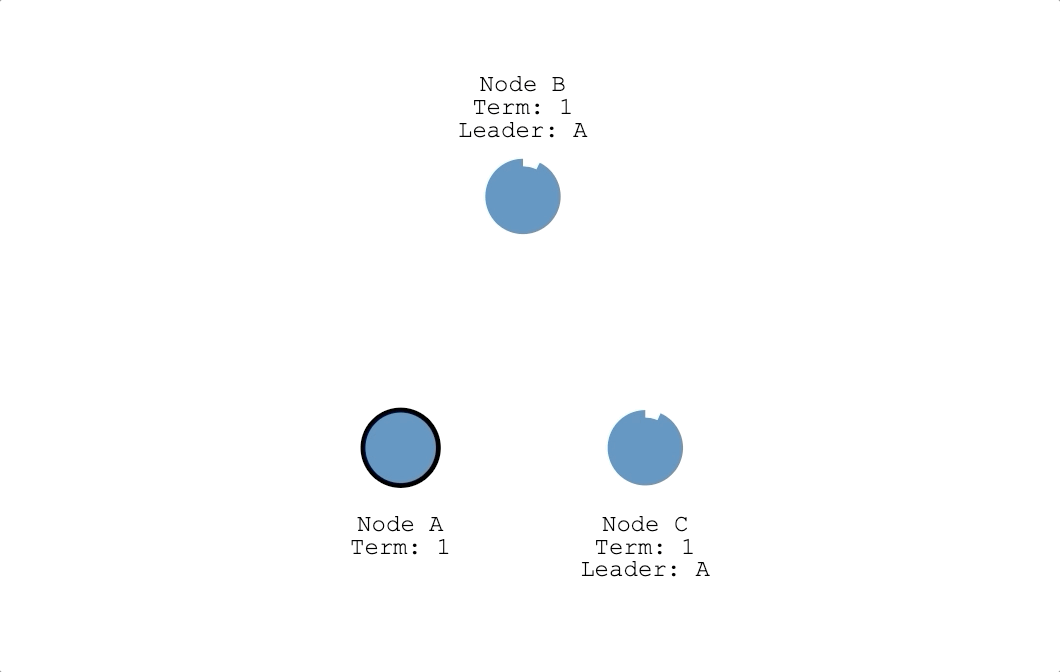
投票原則
上面是節點在三種狀態下可能會遇到的情況,接下來說明節點遇到投票請求(RequestVote RPC)時,會怎麼投票:
- 任期高的不投給任期低,日誌索引高的不投給日誌索引低的節點,這點是為了確保只有日誌最完整的節點可以成為領導者。
- 若候選人滿足上一點,節點會優先投給最早發送投票請求的候選人。
- 每個節點在一個任期內,只能投一張票。
日誌複製(Log Replication)
上面有提到從寫進日誌(Log)到改變資料狀態機(State Machine)是有條件的,這一節會說明 Raft 如何進行日誌複製,並改變資料狀態機。由於 Raft 是強領導者模型,所以也只有領導者可以接收客戶端的寫入請求進行處理,領導者收到客戶端的請求後,會把客戶端的指令寫進日誌,接下來進行發送日誌複製請求(AppendEntries RPC)給其他節點,只要領導者收到超過半數的成功回覆,領導者就會執行這條日誌的指令(Command),改變自己的資料狀態機,並回覆成功給客戶端。
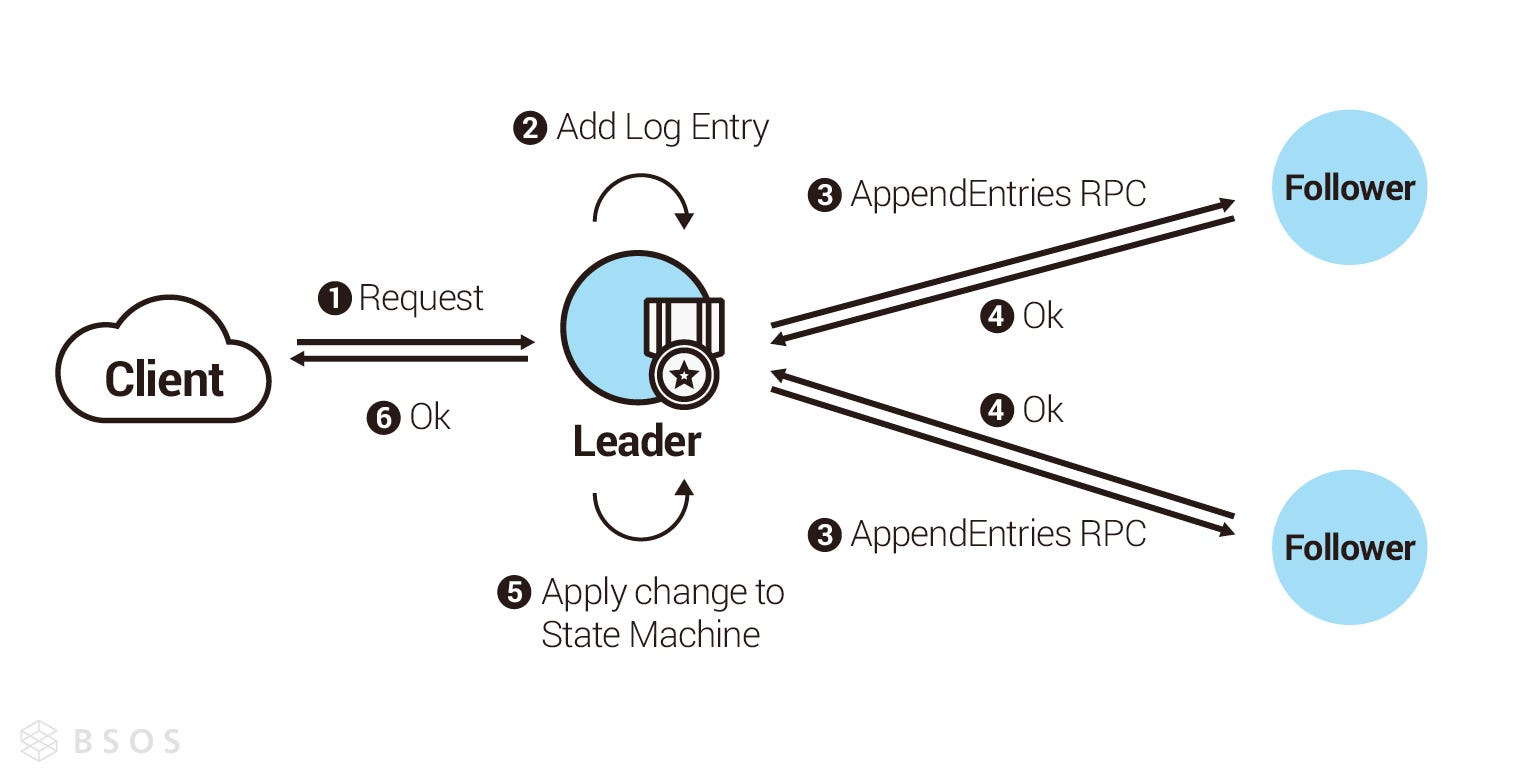
上述情況是個理想的情況,但現實中可能因為各種問題,造成每個 Follower 的日誌不一致(如下圖)。 Raft 在日誌複製請求(AppendEntries RPC)的設計上,不允許直接複製最新的日誌,而跳過中間尚未複製的日誌。如下圖領導者如果發送索引 8 的日誌複製請求給第一個跟隨者,這個跟隨者目前最新的日誌只有到索引 5,所以會拒絕領導者的請求,此時領導者會繼續發送索引 7 的日誌複製請求給第一個跟隨者,跟隨者一樣會拒絕,直到領導者發送索引 6 的日誌複製請求給第一個跟隨者時,跟隨者才會接受,並從索引 6 開始重新同步到索引 8 。


所以如果 Raft 集群要對外服務,則至少要有一半以上的節點有完備的日誌記錄時,才可以對外服務,因為沒有完備日誌記錄的節點,就無法對最新寫進日誌的要求回覆成功。
Raft 設計巧思
說完了 Raft 運作的機制,我們回過頭來看 Raft 設計上的兩個巧思 — 選舉超時時間隨機、兩階段提交優化以及分區容錯。
超時時間隨機(Randomized timeout)
從跟隨者到候選人的 GIF 可以發現,每個節點的計時器倒數的時間是不一樣的,所以有的節點比較快變成候選人,有的則還在倒數,這樣的設計是為了避免節點們同時發起投票,導致票數分散,進而造成選舉失敗,大家還記得上面有說,每個選舉任期只有在有領導者之後才能對外服務,所以 Raft 要盡量保證選舉可以成功,另外為了避免節點頻繁發起選舉,Raft 論文建議把超時設定在 150–300ms 之間。
兩階段提交優化
在上一篇我們有提到,兩階段提交應該要在集群都完成執行階段(Commit Phase)後,才回覆給客戶端,不過在 Raft 裡面,只有領導者完成了執行階段就回覆給客戶端了,所以等於省略的一半的訊息傳播,這是 Raft 的一個優化。
不過大家一定會想,那跟隨者們怎麼知道什麼時候可以進行執行階段?大家還記得我們前面提到的心跳信息嗎?其實心跳信息也是日誌複製請求信息(AppendEntries RPC),而日誌請求信息裡面會帶 leaderCommit,代表領導者目前最新進入執行階段的日誌索引(Index),所以領導者在傳播心跳信息時,不僅是通知跟隨者們不要發起選舉,同時也在進行日誌複製以及同步資料狀態機(State Machine)的狀態,藉此降低過多的信息量。
分區容錯(Partition Tolerance)
大家經過上一篇後,一定會好奇 Raft 怎麼處理分區容錯的問題,以下面的 GIF 為例,Raft 集群再發生分區後,確實可能產生兩個領導者,導致腦裂的問題,不過我們上面有提到,日誌複製只有在大多數節點成功響應之後,領導者才會回傳成功給客戶端,所以不管分區怎麼切,至多只會有一個分區有超過一半的節點,因此也只有一個領導者可以繼續對外服務,其他的領導者即使接到客戶端的請求,也只能回覆失敗。

總結
上一篇我們提到,兩階段提交可以讓集群內大多數節點的狀態維持一致,達到強一致性,Raft 對經典的兩階段提交做了優化,讓達成強一致性的流程更為簡單;在拜占庭容錯算法 PBFT 裡,則是把兩階段提交提升為三階段提交,透過改變流程避免部分節點作惡,造成無法共識。
希望經過這篇文章,可以讓讀者理解 Raft 演算法的運作方式,Raft 在 2014 年發表後就迅速獲得許多系統採用的其中一個原因就是好理解,另一個原因是 Raft 在實作上完美的與系統解耦(Decouple),讓系統可以基於 Raft 做開發,其他共識機制像是 Zookeeper 的 ZAB,在發表之初就是為了 Zookeeper 服務的,所以其他系統比較難基於 ZAB 之上做開發。
Raft 在線上有許多教材及各種語言的實作版本,大家如果有想進一步了解,很推薦直接看論文,如果大家覺得直接看論文太刺激的話,也可以看作者在伊利諾大學(University of Illinois Urbana-Champaign)親自講解 Raft 的影片,最後如果想深入原始碼研究的話,可以研究 Hashicorp 的版本,原因是這個版本已經被應用在各大系統如 Consul 、 IPFS 及 InfluxDB 。
參考
免責聲明:本文只為提供市場訊息,所有內容及觀點僅供參考,不構成投資建議,不代表區塊客觀點和立場。投資者應自行決策與交易,對投資者交易形成的直接或間接損失,作者及區塊客將不承擔任何責任。










